#JavaScript & #SEO: The Basics and Tips to Get Indexed

What is JavaScript?
The 5th most popular programming language in the world, according to inc.com, that is used to program (i.e. change, manipulate things…) in web browsers and servers.
A couple quick facts about JavaScript:
- It has nothing to do with Java. They are two different languages (long story…)
- It was originally developed to run on web browsers (“client-side rendering”) to enhance the HTML and CSS experience. As these programs got more intricate and resource-hungry to process all this new stuff, people looked to server-side rendering to do all of this processing and rendering before it hits the browser, There are benefits and drawbacks to this however which we will discuss later under “recommendations”
How is JavaScript used on a webpage?
In basic terms, a webpage is made up of these ingredients;
- HTML, which provides the elements like text, headings, images, links.
- CSS which formats and styles these elements in different colours, positions.
- JavaScript, which can pull in HTML and apply CSS styling based on either user actions (see next product results / activate an animation) or based on pre-programmed actions from a developer (change slide image after 2 seconds, update cinema listings when current listings expire).
Think about when you scroll down twitter and new tweets are loaded, that’s JavaScript. Most websites use this for loading new products / blog posts as you scroll or if you click a button.
There are more complicated uses of JavaScript such as web apps like Google Maps, some of which mostly or completely rely on the use of JavaScript.
JavaScript and SEO
Before we go into the relationship between JavaScript and SEO we should look at the process that needs to happen to ensure that a webpage gets into Search Engine Results pages. As Technical SEOs we perform audits and work with our developers to ensure this process happens without a hitch:

- Crawl: Find and read everything on your webpage
- Render: Understand what all the JavaScript / CSS / HTML elements are doing
- Index: Save all of it
- Rank: Display you somewhere in the search engine results pages
All 4 stages have their own unique challenges and optimisation techniques to ensure the best possible search result is displayed to the user. However, for now we are going to focus on the ‘crawl’ and ‘render’ stages.
Crawling and Rendering (JavaScript, HTML, CSS)
Google is mostly concerned about the user’s experience, so it wants to see how a complete web page looks like to the user. When all the HTML, CSS and JavaScript functionality is loaded, what does that final page look like?
So, in order to do this, Google uses its software called Googlebot to ‘fetch’ the page then it uses a Web Rendering Service (WRS) which ‘renders’ it.
- Rendering means taking the code and elements from a page and interpreting it into what a user would visually see in their browser
The bot ( or ‘crawler’ or ‘spider’ as they are also known) needs to find the content via internal links and unique URLs. Sometimes these are not provided in a page built a certain way with JavaScript, so you already lose out on some content being indexed and contributing to your ranking position in Google.
Google’s WRS then tries to replicate how a user may see the page by rendering it and noting whether you have restricted Google from seeing certain parts of the page, for example, whether you blocked JavaScript libraries or other resources that contribute towards how the final page version looks.
It’s worth noting that Google doesn’t crawl the JavaScript parts of the page in the first run. It defers this action to later on when it has resources free to do so as this process takes much more resource then rendering a simple HTML+CSS page
Just going back to that process of how Google crawls and indexes your site, if your site has JavaScript, Google will use the DOM during the ‘render’ stage.
- The DOM (document object model) is a complete picture of the code behind a webpage. If your content is dynamic (it relies on HTML, CSS and JavaScript) then right-clicking on “view source” will only show you part of the code, not the dynamic functionality bits. Google, as well as Bing and Baidu, uses the DOM to figure out what the final page looks like and how it functions when it is fetching and rendering.
Here are those stages again to see where this action fits:
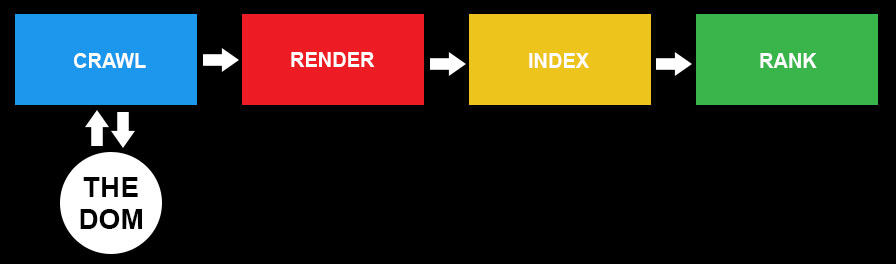
- Crawl: Find and read everything on your webpage
- Render: Uses DOM to understand what JavaScript / CSS / HTML elements are doing
- Index: Save all of it
- Rank: Display you somewhere in the search engine results pages
Although Google has gotten better at rendering pages to figure out how these look to humans and pick up on all the JavaScript functions manipulating content, the current WRS it uses is based on an older version of Google Chrome, Chrome 41. This was released in 2015, the latest version is Chrome 67, so it is a bit dated relative to how fast JavaScript is being updated. For example, in newer JavaScript versions there are certain features and coding conventions that are not supported in this earlier Chrome version.
How to ensure JavaScript content is SEO Friendly?

When building websites, web developers will focus on creating the best user experience possible, delivering high accessibility, functionality and speed. Users and Google demand this, so web development projects should of course lead with this goal in mind. But in parallel to this or directly afterwards, we recommend that there should be some diagnosis and optimisation done to ensure Google can crawl, render and index the content, ensuring the site’s SEO optimisation potential is as high as possible.
A few recommendations:
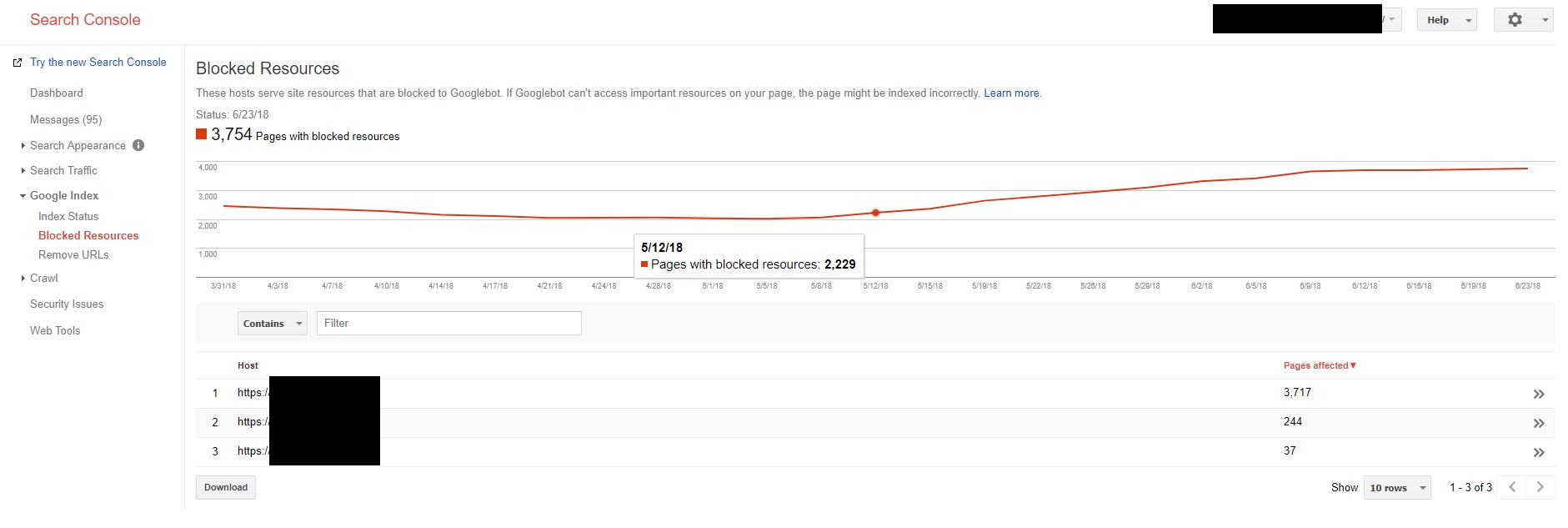
- Check Google Search Console’s “blocked resources” section to see what it recommends you should reveal and confirm these are functions that affect how content is displayed to the user:

- Either remove a disallow statement in your robots.txt file for a whole folder housing the scripts, or if some in that folder need to remain hidden, ‘disallow’ the folder and ‘allow’ specific filesFirst and foremost, if you use any JavaScript that dynamically changes the content on a page (e.g. click for next page, reveal content, change title tag and meta description) don’t block the resources for the scripts that drive this functionality in your robots.txt file.
- Ensure all of your internal links are written within an HTML ‘A tag’ (e.g. <a href=“/another-page”>…) as Google can definitely crawl these, allowing it to then follow a journey via these links through the site and discover all of the pages that exist. If you use JavaScript ‘onclick’ events to take a user to a new page Google will have a tough time identifying these as links (e.g. onclick=”myFunction()”> ).
- If your website generates new content, such as click for next page or load more products for example, but doesn’t change the URL then this is a problem as Google wont’ be able to see this newly generated content.
- Just quickly, if you were thinking of using fragment identifiers with hash bang (“#!” AJAX crawling scheme, e.g. “something.com/cars.php#!audi) this will no longer be supported from Q2 2018
- Consider setting up a HTML fallback for functions like “read more” of “load more products”, so that when you turn off JavaScript in a browser the buttons are HTML with <a href=””> tags the next pages are paginated on new URLs, this might be the easiest was to resolve this type of issue. See some resource on this
- Another solution for this as an alternative to the above is to generate clean URLs for when content changes on one page, so that Google and Bing can crawl them, you can do this by using “pushstate History API”, see some resource on this
- If you are running a lot of scripts on the client-side and having trouble getting them all rendered in Google, consider Pre-rendering or server-side rendering:
- Pre-rendering: this is when a cached version of a page is served, a snapshot if you will. It’s slightly better than serving the DOM version as you are taking the rendering step out. One drawback to this method might be that the data could be minutes out of date, an issue if you have pages that need to be constantly updated. Another drawback is that sometimes you may have noticed last minute changes to styling to the content when you load (colour, format, position changes all of a sudden). Check out this resource on pre-rendering for further reading.
- Server-side rendering: is literally what is sounds like, the server takes care of it all, rendering everything before sending a page to the browser. This works well for SEO as you can be sure all JavaScript elements are rendered and returned from the server. You also end up with a slightly faster initial page load. However, you may miss out on some of the rich features that client-side rendering provides.
- Combine both: you could consider using a combination of both to make use of the speed, SEO and rich functionality benefits. Here is a good blog post on the comparisons of both techniques and further reading.
Testing your SEO-Friendly JavaScript
There are several ways you can diagnose and test your code to ensure as much of it is getting indexed as possible:
Free tools:
- Use Google Search Console’s fetch and render tool – will flag up whether the pages load fully or partially with errors. One drawback to this tool is the test can allow for over 5 seconds to test a fetch and render a page, which doesn’t help if you are testing how fast you can get this process down to (ideally under 5 seconds)
- Test if your JavaScript is compatible with Chrome 41 (remember, Google is using this version of Chrome as a reference to test how your JavaScript renders to users). You can use this tool for testing if your features are supported in Chrome 41 and will compare compatibility to latest browser versions too: https://caniuse.com/#compare=chrome+41
- Debug your site using the Rich Results tool – this tool renders your pages and reveals the final code with any errors
- Use Chrome developer tools to test JavaScript (errors and page/script load times) – this fantastic guide talks you through this
Paid tools:
- DeepCawl will can now crawl and render JavaScript on your site (they charge a monthly fee for their toolm this feature is an add-on). The feature works quite well as I tested this from beta to live final version – see their guide
- Screaming Frog also have this feature, the tool has a one-off charge per user and the feature is included – see this guide
If you have a website that may be loosing SEO visibility due to content not being fully indexed or down to usability issues, get in touch today to see how our Technical SEO team can help.







